// article
GLUE and the Transformer Leap
22.67 points: what the field bought by dropping the recurrence
Average a Transformer’s GLUE scores and you get 86.91. Average an LSTM’s and you get 64.25. That is a 22.67-point gap, the single largest structural fact in this little table. Not 2 points, not 5. Almost twenty-three, on a 0 to 100 scale, between two ways of encoding a sentence. I went looking for nuance and mostly found a wall.
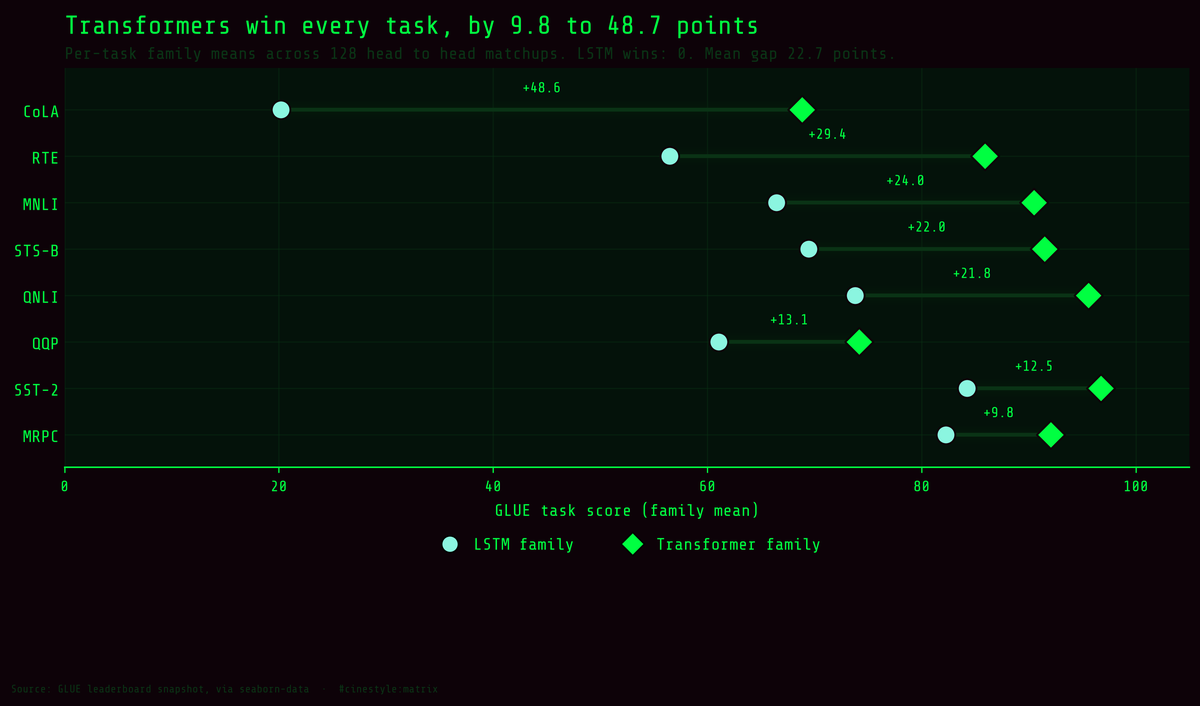
Every row above tells the same story. The Transformer dot is always to the right, the line between them is the gap, and across 128 head-to-head matchups the recurrent side wins exactly zero. The rest of this post is me taking that picture apart.
The data is a frozen GLUE leaderboard snapshot from seaborn-data: 64 rows, 8 models times 8 tasks, each row tagged with a year (2017 to 2019) and an encoder family (LSTM or Transformer). Four models are BiLSTM variants, plain BiLSTM plus the ELMo, CoVe, and attention-augmented cousins. The other four are BERT, RoBERTa, ERNIE, and T5. It is a period piece. It predates instruction tuning, the scores are leaderboard numbers I did not reproduce, and eight models is a snapshot, not a population. But the architecture transition it captures is real, and the size of it surprised me.
The gap is everywhere, but not evenly
Break the 22.67 apart task by task and the average turns out to be hiding a 5x range. Here is the Transformer-mean-minus-LSTM-mean gap, per task:
- CoLA: 48.65
- RTE: 29.45
- MNLI: 24.05
- STS-B: 22.02
- QNLI: 21.78
- QQP: 13.10
- SST-2: 12.47
- MRPC: 9.80
CoLA is the runaway. The Transformers average 68.85 on it; the LSTMs average 20.20. That is not “better at the task,” that is one family doing the task and the other essentially failing it. CoLA is grammatical-acceptability judgment scored by correlation, and a model that has not learned the grammar lands near zero. The recurrent encoders, even the ELMo-boosted one, never climbed off the floor. Attention buys the most exactly where you have to track long-range syntactic structure.
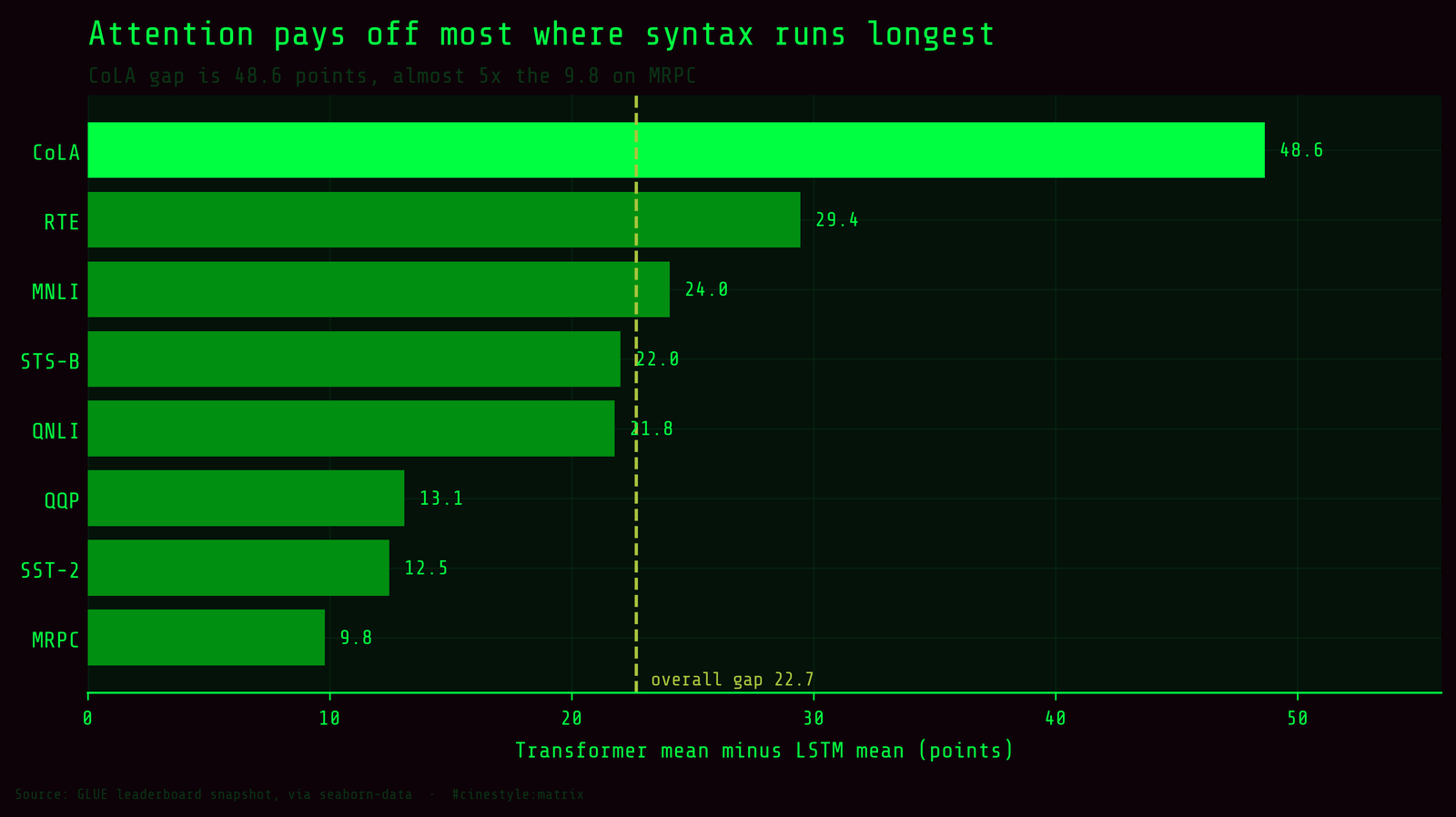
At the other end sits MRPC, where the gap shrinks to 9.8. MRPC is paraphrase detection with a high floor: the LSTMs average 82.28 and the Transformers 92.08, so both families clear 80 and the daylight between them is narrow. When a task is close to saturated and does not lean hard on long-distance dependencies, the architecture matters least. SST-2 (sentiment, 12.47) and QQP (question-pair similarity, 13.10) sit nearby. So the tasks where attention pays off most are the ones an LSTM was structurally worst at, and the tasks where it pays off least are the ones a bag-of-context model could already mostly handle. The task that needs the longest memory is the task the memoryless model wins by the widest margin.
25 points in two years
Line the scores up by year and the trajectory is steep. Mean score across every task row:
- 2017: 63.26
- 2018: 74.47
- 2019: 88.64
That is a 25.38-point climb from 2017 to 2019. The 2017 cohort is entirely recurrent (BiLSTM, BiLSTM+Attn, BiLSTM+CoVe). 2019 is entirely Transformer (RoBERTa, ERNIE, T5). The line in the second figure is not a smooth technological drift; it is a substitution. The field did not make LSTMs 25 points better. It stopped using them.
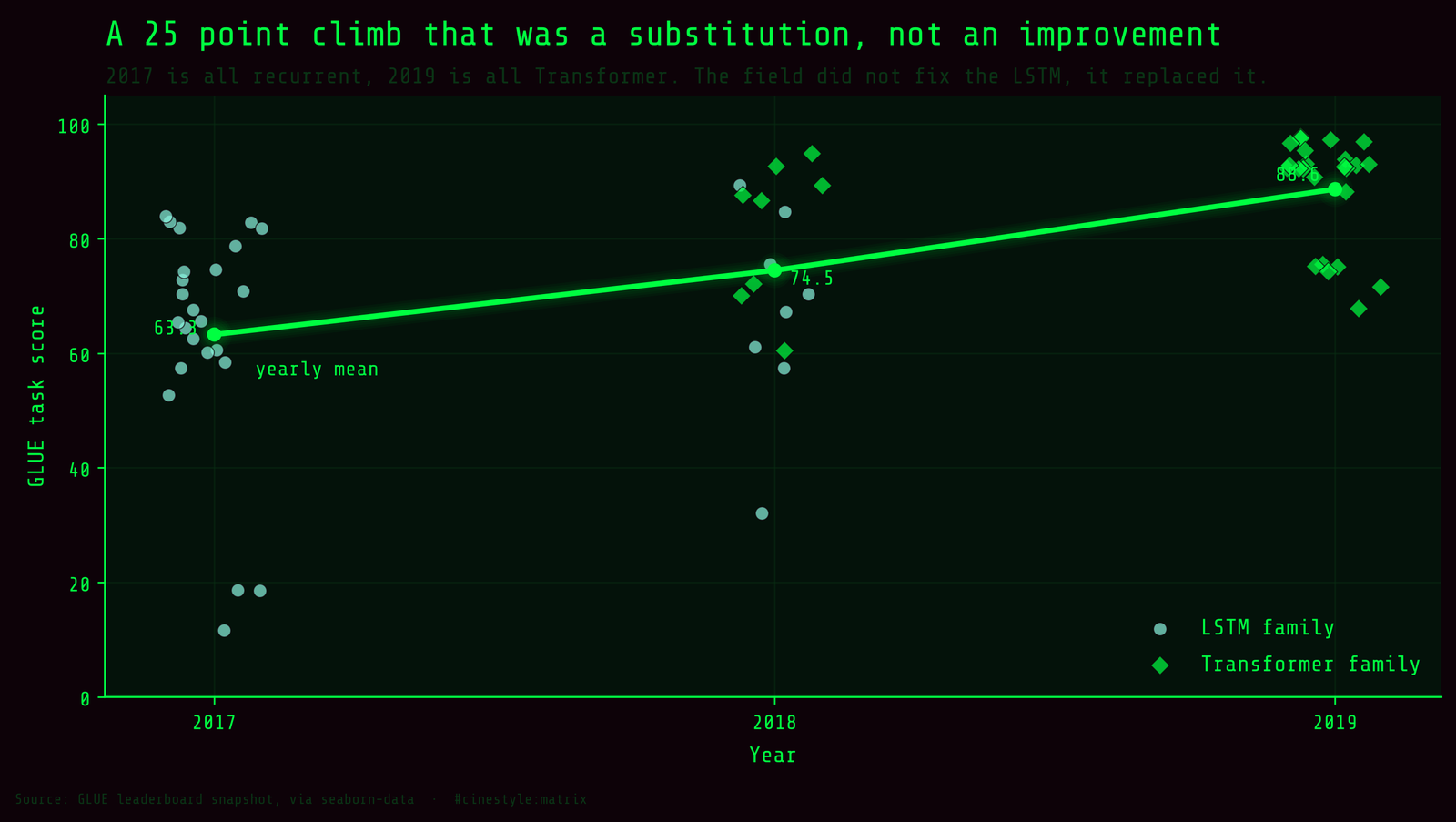
Here is where I have to be honest about what this analysis cannot separate. Every Transformer in the table is from 2018 or 2019. Every LSTM is from 2017 or 2018. The two families barely overlap in time, and the Transformers are also the bigger, more heavily pretrained models. So the 22.67-point “encoder gap” is tangled up with year and with scale. I cannot hand you a clean controlled contrast that says “hold everything else fixed, swap the encoder, gain 22.67.” Nobody trained a 2019-scale BiLSTM at RoBERTa’s parameter count to find out. The one year where both families appear is 2018, with BERT on the Transformer side and BiLSTM+ELMo on the LSTM side, and even there it is one model each, so it confirms the direction without isolating the cause. The honest reading is that “Transformer,” “newer,” and “bigger” all move together here. This table cannot pull them apart.
I went looking for an upset and did not find one
The thing I actually wanted from this data was a counterexample. Benchmarks almost always have one, some task where the old architecture, on its home turf, sneaks past the new one. So I checked every LSTM model against every Transformer model on every task: 4 x 4 x 8 = 128 head-to-head matchups.
Zero. Not one LSTM model beats one Transformer model on a single task. No ties either. The best the recurrent side ever does is MRPC, where BiLSTM+ELMo hits 84.7, and the worst-performing Transformer on MRPC still clears it. The closest the families come on any task is a 4.6-point Transformer cushion, and that is the minimum across the whole board. By overall mean it is starker still: the best LSTM in the table, BiLSTM+ELMo at 67.20, trails the worst Transformer, BERT at 81.74, by 14.54 points. The weakest member of the new guard beats the strongest of the old by more than fourteen.
That is a cleaner separation than I expected and, frankly, a little boring as a finding. No plot twist, no scrappy LSTM holding the line on its specialty. But the absence is the result. When a snapshot of a field shows two architectures with no overlap at all across 128 comparisons, the transition was not a gradual handoff where the old approach kept a few niches. It was a clean break.
What I cannot tell you from 64 rows is how much of that break is attention and how much is scale and pretraining riding in on the same models. The table will not say. What it will say is that by 2019, on this benchmark, the recurrent encoder had stopped winning anything at all. The one task where the two families came closest, MRPC, is the one where the sentences are shortest and the grammar matters least.