// article
Old Faithful's Two Modes
Old Faithful is two geysers wearing a trench coat
Two cluster centers fall out of the data at (2.04 min eruption, 54.5 min wait) and (4.29 min, 80.0 min). That is the whole story. Old Faithful does not erupt for “about three and a half minutes give or take.” It does one of two things: a short pop followed by a short wait, or a long blast followed by a long wait. The middle is nearly empty.
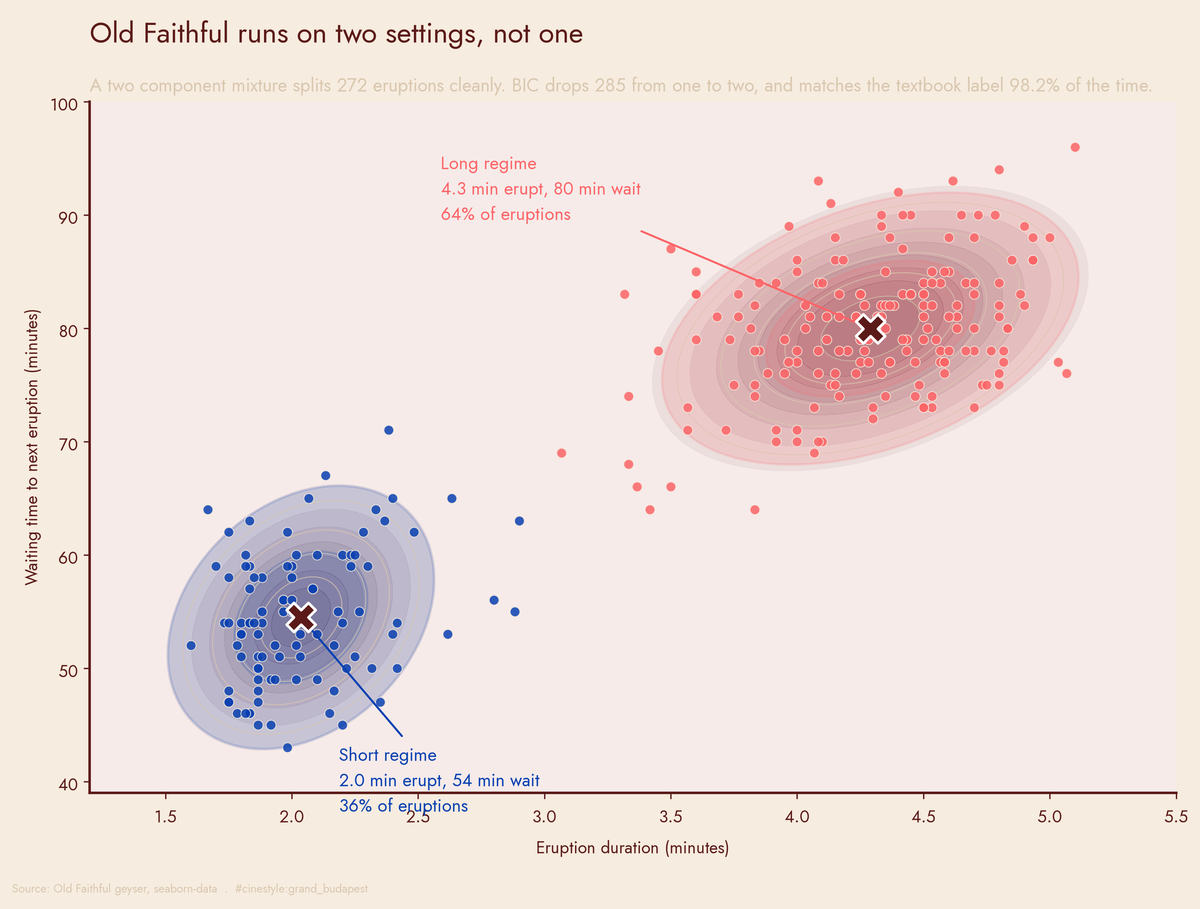
I went in expecting noise around a single mean. I came out with a histogram that has a hole in it. The picture above is the entire argument: fit two Gaussians to the raw duration and waiting pairs, and the geyser sorts itself into two clouds with daylight between them.
The data
load("geyser") from seaborn-data: 272 eruptions of Old Faithful, three columns. duration is how long the eruption lasted in minutes, waiting is the gap to the next one, and kind is a pre-baked short or long label that came with the set. Small, clean, and old enough to be in every intro stats textbook. I will get to why that is both the point and the catch.
First thing I always do with a single variable is plot its distribution and look for one peak. Here I got two. The duration density has modes at 1.99 and 4.37 minutes with a clear trough between them at 3.00 minutes. Waiting does the same thing: peaks near 53.8 and 79.9 minutes, dip at 65.5. Both columns are bimodal on their own, before I have clustered anything.
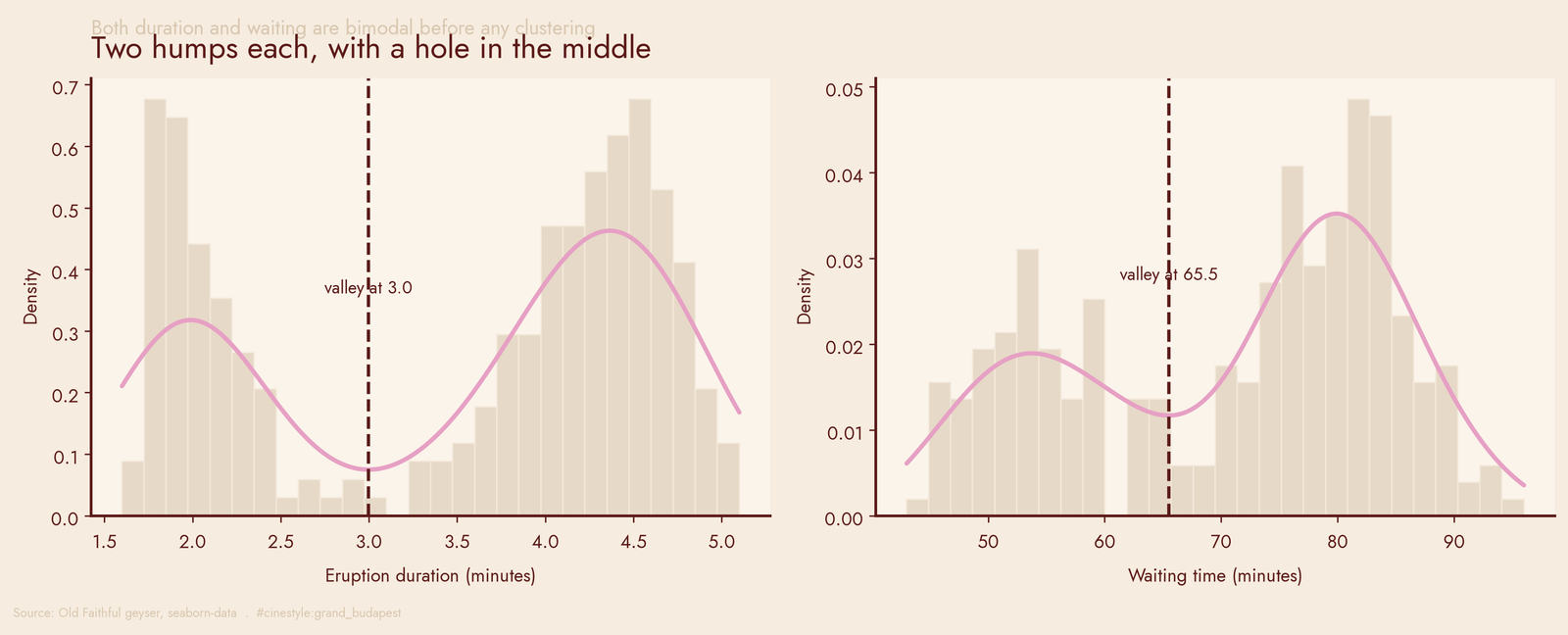
Look at the dip in the left panel. If duration were one process with spread, you would see a single hump, maybe skewed. Instead there is a valley right where the average would be. Only about a third of eruptions, 36%, land below the duration dip. The short regime is the minority, and the data already knows which eruptions belong to it before any model touches it.
The model that did not need to be deep
You could throw a neural net at this. You would be embarrassing yourself. A two-component Gaussian mixture on the raw (duration, waiting) pairs nails it.
I fit GaussianMixture(n_components=2) from scikit-learn, full covariance, ten restarts. It converged. The two components:
- Short regime: center at 2.04 min, 54.5 min wait, mixing weight 0.356.
- Long regime: center at 4.29 min, 80.0 min wait, mixing weight 0.644.
So roughly 36% of eruptions are short-short and 64% are long-long. Those weights match the histogram dip almost exactly. The kernel density estimate and the mixture model found the same split without sharing any code.
The regime structure is physical, not statistical sleight of hand. A short eruption does not fully drain the chamber, so it refills faster and you wait less. A long eruption empties the chamber, so the next one takes longer to build. The mean wait in the short cluster is 54.5 minutes; in the long cluster it is 80.0. The duration centers, 2.04 against 4.29, are more than two minutes apart, about double. Two Gaussians describe a plumbing system, not a curve fit.
Does the model agree with the label that came in the box?
The dataset ships a kind column. I never showed it to the mixture model. So how often does my unsupervised cluster assignment match the human label?
267 out of 272. That is 98.2% agreement.
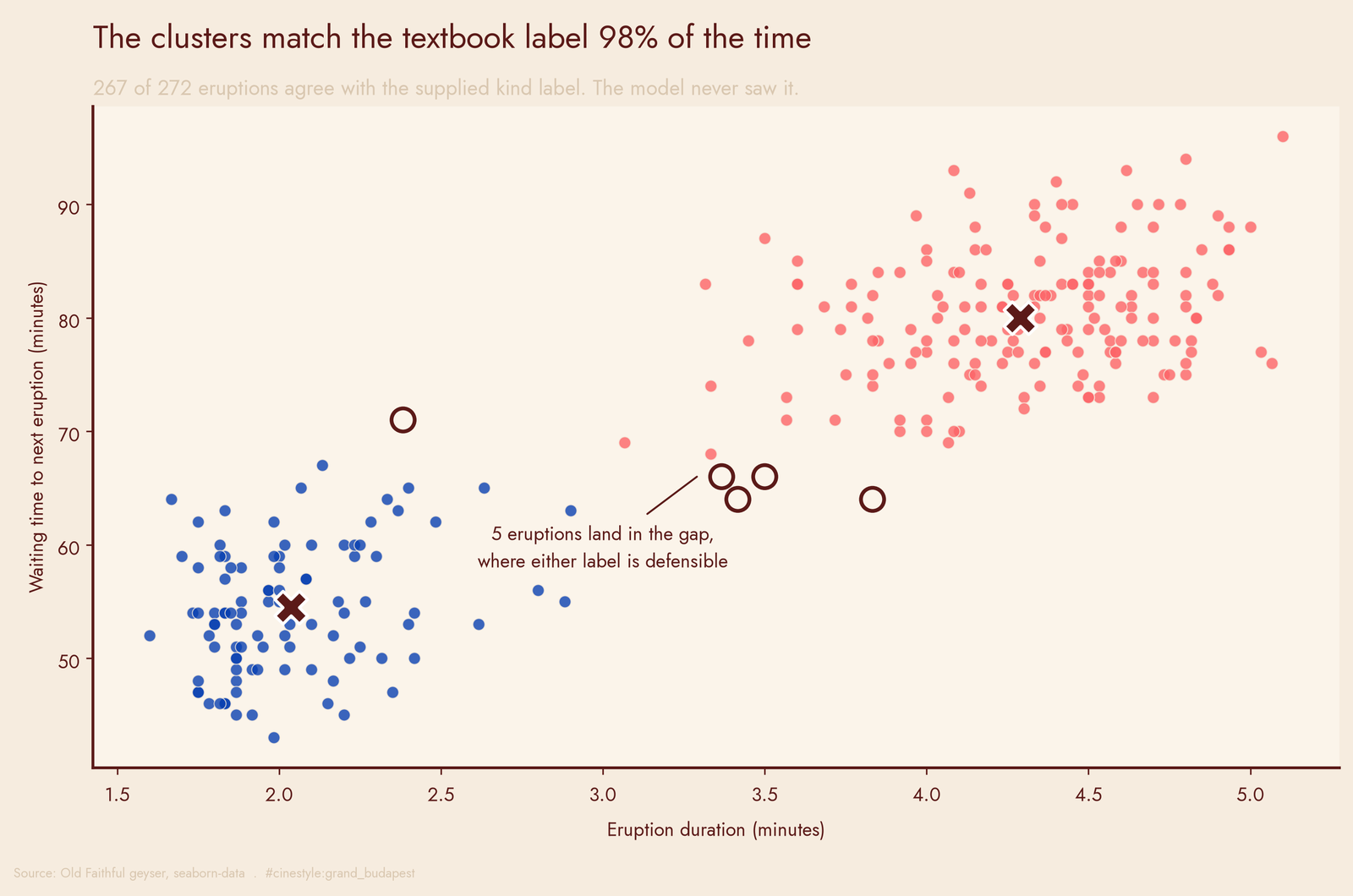
The five eruptions that disagree are the circled points in the scatter, sitting in the gap between blobs, where a 2.5-minute eruption could plausibly belong to either camp. The model and the label only disagree on the genuinely ambiguous cases. Where the physics is decisive, they agree.
That is the part I re-ran twice. An unsupervised method recovering a supervised label at 98% is the sort of result that usually means I leaked the label somewhere. I did not. The mixture only ever saw two numeric columns. The clusters are just that clean.
What about a plain line?
Before the clustering, the obvious move is to regress waiting on duration. Longer eruptions, longer waits, fit a line, done. And it works fine: slope 10.73, meaning each extra minute of eruption buys you about 10.7 more minutes before the next one. R-squared is 0.811, Pearson r is 0.901. By normal standards that is a strong fit and you would ship it.
But a line is the wrong mental model here, even at R-squared 0.81. The relationship is not a smooth ramp where 3-minute eruptions sit halfway up. It is two clouds that happen to lie along a diagonal. The line is fitting the gap between the clusters as if it were signal. Almost no eruptions actually live near the regression line’s middle, because almost no eruptions are 3 minutes long. The high R-squared is real but it is flattering. It measures the separation between two groups and calls it a trend.
Why two and not three
To make sure I was not just seeing what I wanted, I let BIC pick the number of components. Lower is better, and it bottomed out hard at two.
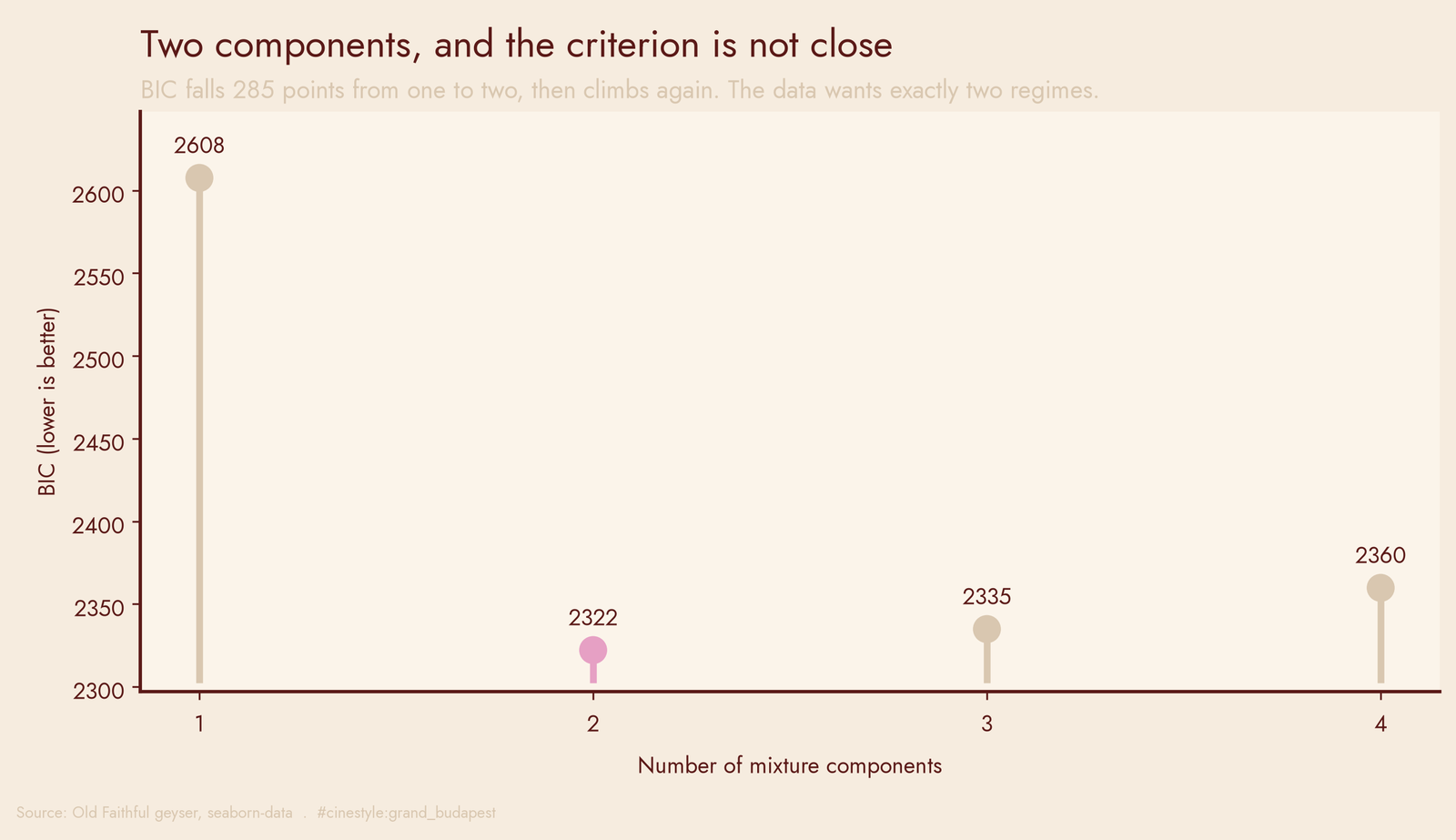
One component scores 2607.6. Two drops to 2322.2, a fall of 285 points, which in BIC terms is not close. Three components creeps back up to 2334.9, four to 2359.8. The data wants exactly two regimes and penalizes you for inventing a third. No tuning, no elbow-squinting. The criterion just says two.
The honest caveat
This is one geyser, 272 eruptions, and a dataset that has been taught in classrooms for forty years precisely because it splits this cleanly. Real-world bimodality rarely arrives this gift-wrapped. Old Faithful’s two regimes come from chamber physics that genuinely toggles; most “two clusters” you will meet in production are messier, with overlapping tails and no tidy kind column to check yourself against. So take the 98.2% as a demonstration that the method works when the structure is there, not a promise that it will be there.
But when the structure is real, you do not need much. Two Gaussians and a BIC check told me everything the geyser had to say, and the most expensive thing I ran was a histogram.