// article
Two Americas of Driving Risk
Two Americas of driving risk, and the insurer charges them the same
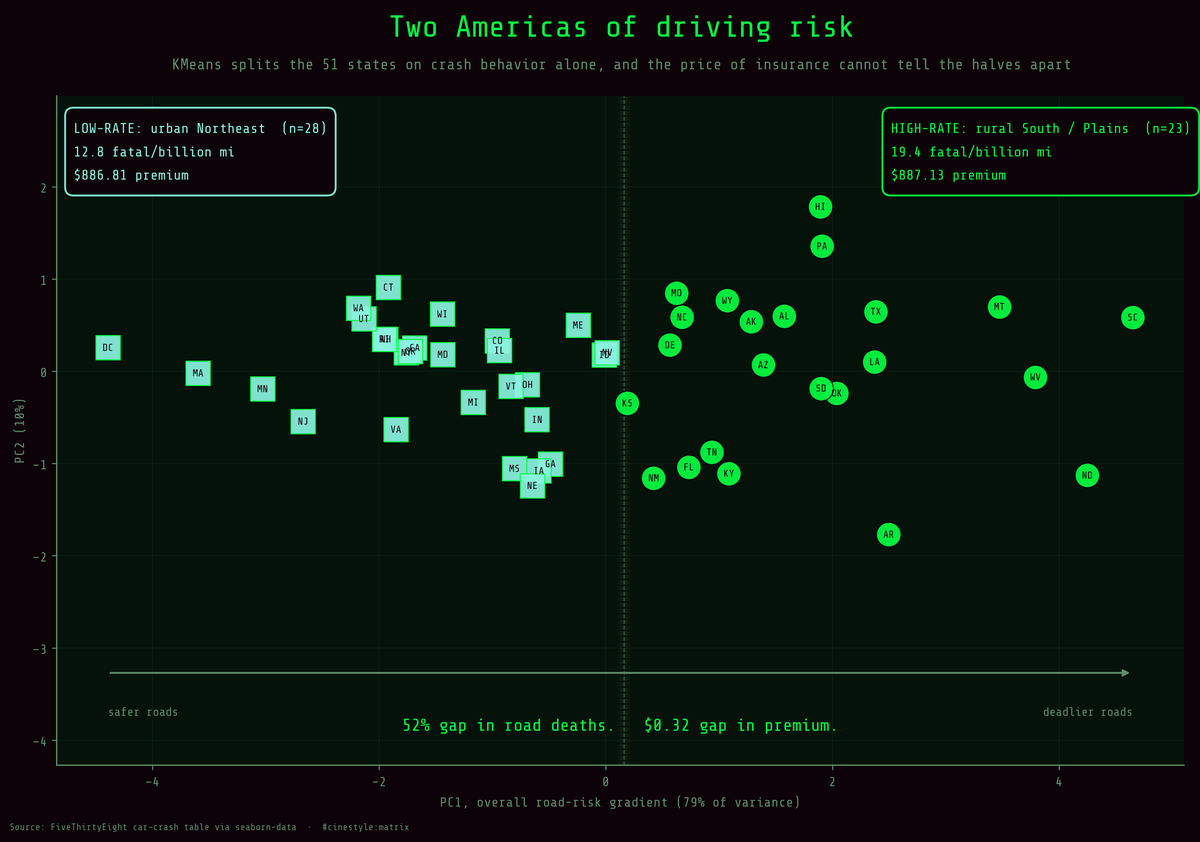
Let the algorithm sort the country on crash behavior alone and it carves out two halves: a low-rate urban Northeast and a high-rate rural South and Plains. The deadlier half kills people on the road 52% faster. The two halves pay for insurance within 32 cents of each other. That single picture is the whole article.
Split the 50 states plus DC into two driving-risk groups and the gap is wide. One cluster averages 19.45 fatal crashes per billion miles, the other 12.79, a 52% difference in how lethal the roads are. The average annual insurance premium in those two groups is $887.13 against $886.81. Thirty-two cents apart.
I was not fishing for that. I came to this dataset wanting to see whether the states sort into clean driving-risk profiles on their own, without me hand-picking a North-versus-South story. So I let KMeans do the splitting and only looked at premiums afterward. The premium tie fell out as a byproduct, and it is the result I keep staring at.
The setup
The data is FiveThirtyEight’s car-crash table via seaborn-data, 51 rows (50 states plus DC, roughly 2009 vintage). I clustered on five columns: total (fatal crashes per billion vehicle-miles) plus the four behavioral shares speeding, alcohol, not_distracted, and no_previous. One caveat up front, because it matters for how you read everything below: only total is a true rate. The other four are percentages of each state’s fatal crashes, so they are partly compositional and tend to ride up with the total. I standardized all five before clustering so no single column’s scale dominates the distance math, but the four shares are correlated enough with total that the clustering is really separating states along one dominant axis.
Picture five rulers all pointing the same direction and you have read the data right. PCA confirms it. The first principal component alone soaks up 79% of the variance, and every feature loads on it with the same sign (total 0.484, no_previous 0.463, alcohol 0.458, not_distracted 0.442, speeding 0.381). That is not five independent risk dimensions. It is one “how bad are this state’s roads” gradient with a little texture on top.
So I did not oversell the structure. I asked for k from 2 to 7 and let the silhouette score pick. It peaked at k=2 (0.4348) and fell off for everything else: 0.3207 at k=3, around 0.30 for k=4 through 7. With n=51, the honest two beats a prettier three.
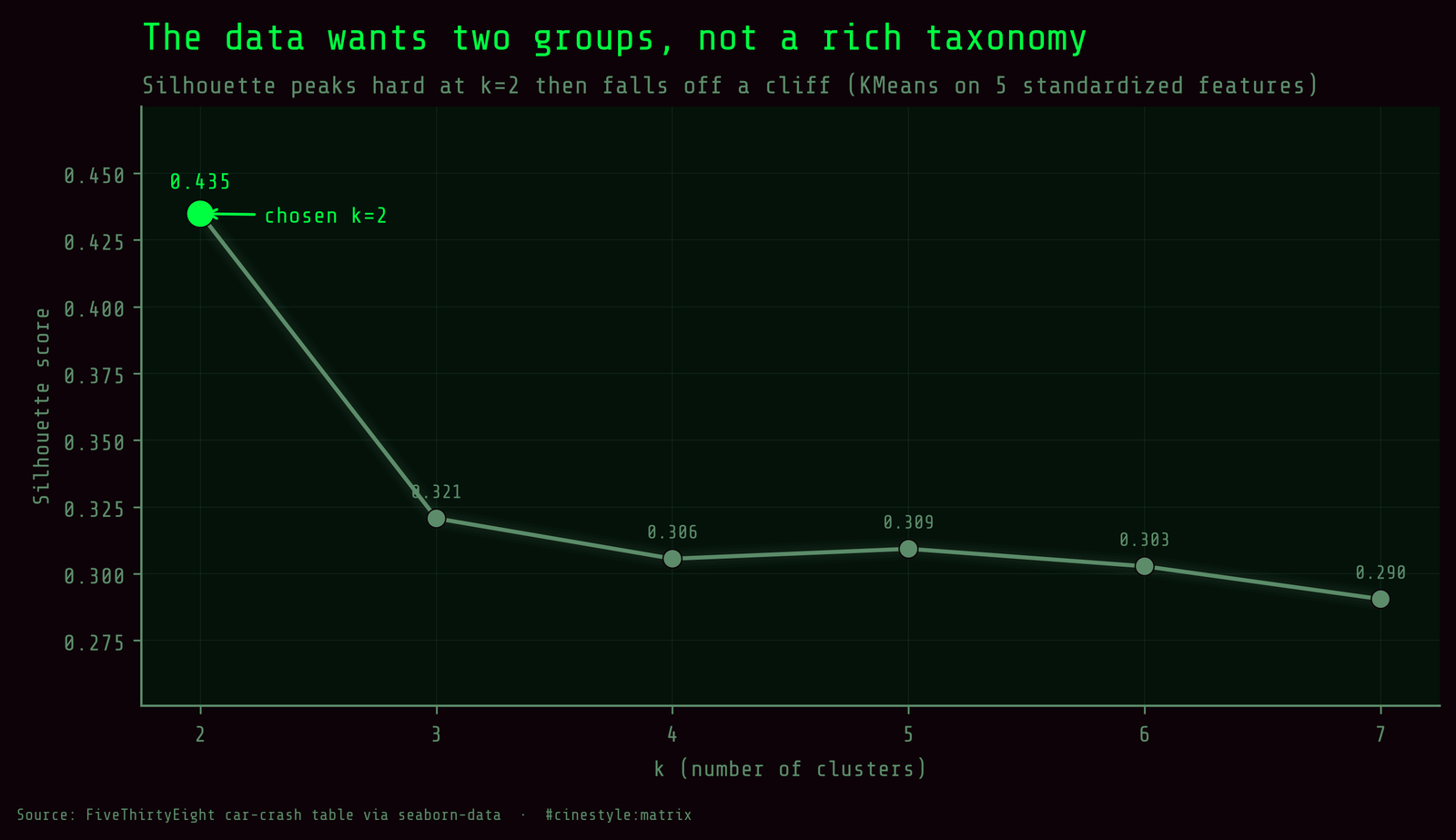
Who is in which bucket
The low-rate cluster has 28 states. The high-rate cluster has 23. Name them by their mean fatal rate and the geography writes itself, even though geography was never an input.
The high-rate group is the rural South, the Mountain West, and the Plains: Alabama, Arkansas, Louisiana, South Carolina, Tennessee, plus Montana, Wyoming, the Dakotas, Oklahoma, New Mexico, Texas. Mississippi lands in the low-rate bucket despite its reputation; the clustering goes on the numbers, not the stereotype. The states closest to that cluster’s centroid, the most prototypical members, are SD, OK, AZ, AL, and TX. Long rural distances and higher speeds, more single-car wrecks on empty roads. Its averages run hot: speeding share 6.49 against 3.77 in the other group, alcohol share 6.19 against 3.82.
The low-rate group is the dense Northeast and the big urban states: New York, New Jersey, Massachusetts, Connecticut, Rhode Island, Maryland, plus California, Illinois, Michigan, Washington. Its most prototypical members are CA, NY, MD, OR, and NH. This is the kind of driving where you crawl through traffic and bend a fender instead of dying on an empty two-lane at speed.
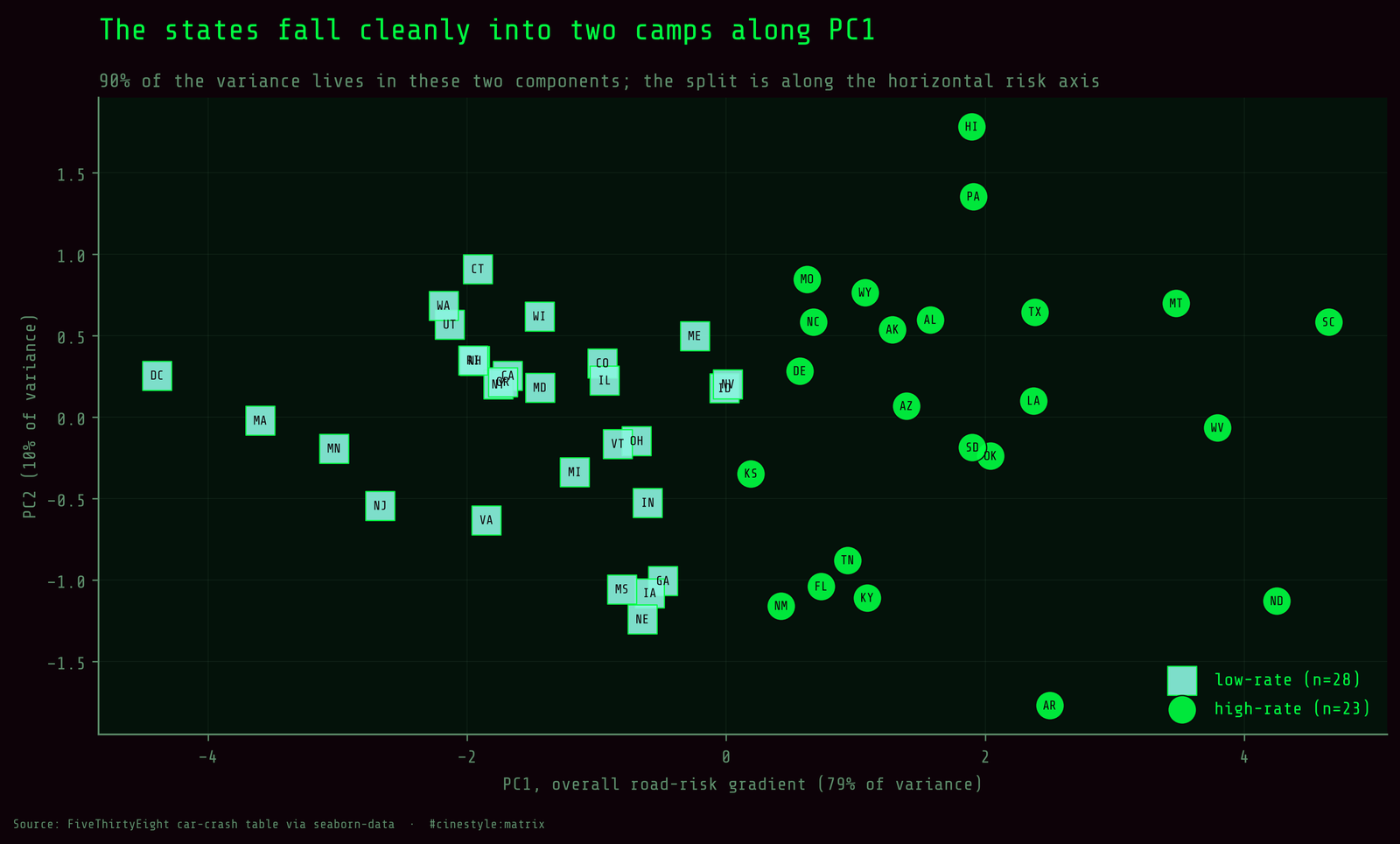
The scatter is what sold me on k=2 being real and not a convenience. The two clusters separate cleanly along PC1, the horizontal axis that is essentially “overall risk.” But look at the seam in the middle and the algorithm made some genuinely close calls. Pennsylvania and Delaware land in the high-rate group despite not feeling especially Southern or rural, and a chunk of the low-rate states pile up near the boundary. A 0.4348 silhouette is moderate, real structure, not two planets. Read these as descriptive buckets with fuzzy edges, nothing more.
One placement is worth flagging. DC sits in the low-rate cluster: a single dense city with a low fatal rate, treated exactly like the urban Northeast it resembles. One of these 51 “states” is not a state.
The premium tie
Now the part I kept coming back to. Two clusters side by side: a 52% gap in fatal-crash rate, and a premium gap of 32 cents.
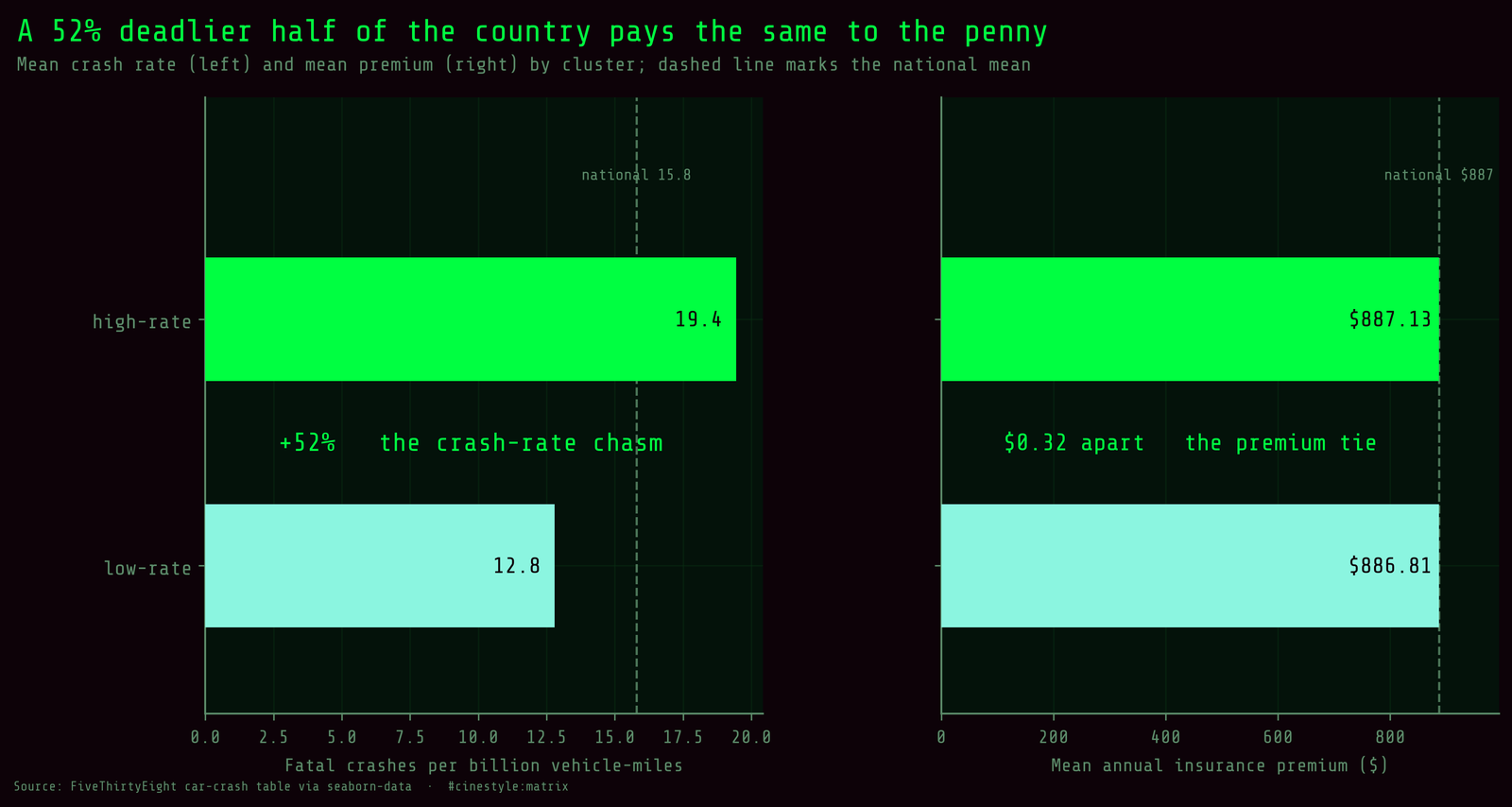
The bar chart makes the point hard to miss. The left panel, crash rate, shows two clearly different bars straddling the national mean of 15.79. The right panel, premium, shows two bars at the same height, both sitting right on the national average of $886.96. If premiums tracked road lethality, that right panel should echo the left one. It does not. Insurance losses per driver barely move either, $136.30 in the high-rate group against $133.01 in the low-rate one, a rounding error next to the crash gap.
The grouping was driven entirely by crash behavior; the premium was never allowed to vote. You can carve the country into its safest and its deadliest driving halves using nothing but crash data, and the price of insurance will not tell the two halves apart.
The reason is not a mystery, and the clustering does not prove it. Premiums price expected payouts, and payouts are dominated by dense, expensive, low-speed urban collisions, the cities sitting in the low-rate group. The rural single-car fatalities that push the high-rate group’s total up are cheaper per incident, even though they kill more people per mile. The premium is measuring a different kind of bad than the crash rate is.
So treat these two clusters as what they are: a descriptive split of 51 rows from one cross-sectional snapshot, not a causal map and not a verdict on any individual driver. If you had asked me to bet that the deadlier-roads half of the country pays more for car insurance, I would have lost. They pay the same to the penny.